As a security researcher, one of my daily tasks is to keep up with the latest security research and trends. I check notification emails from google scholar, arxiv, and other platforms everyday and think about possible rising-star topics.
Then, one idea popped into my head.
Can we extract keywords from security papers to discover the most popular topics each year? What lifecycle did these topics go through in history?
Finally, here comes the toy project,
SecTrend Analysis
. In this project, I collect 17,797 security papers from 18 security conferences(1980-2020) and analyse them from data-driven perspectives.
1. Data Collection
We focus on tier1(6) and tier2(12) security conferences presented on
Computer Security Conference Ranking and Statistic
and extract corresponding paper metadata from
dblp
.
The 18 conferences are
S&P (Oakland), CCS, Security, NDSS, Crypto, Eurocrypt, ESORICS, RAID, ACSAC, DSN, IMC, ASIACCS, PETS, EuroS&P, CSF (CSFW), Asiacrypt, TCC, and CHES
. Dblp is a computer science bibliography website. Data released by dblp are testified to be
highly accurate
and
acceptable complete
. And all dblp data are under the
CC0 1.0 Public Domain Dedication license
, which means people are free to copy, distribute, use, modify, transform, and produce derived works from their data.
In dblp, a conference, e.g. S&P, is composed of multiple proceedings, e.g. S&P2020 . Each proceeding page contains the bibliographic information of papers on the proceedings and can be accessed by dblp api, such as https://dblp.uni-trier.de/search/publ/api?q=toc%3Adb/conf/sp/sp2020.bht%3A&h=1000&format=json . We manually gather dblp links of 18 security conferences, crawl proceedings and the related paper metadata of it. You can get the whole dataset from page Dataset .
In this way, we obtain 17,797 papers from 1980 to 2020 with 18 conferences and 529 proceedings.
| venue | tier | item_cnt | paper_cnt | min(year) | max(year) | year_cnt | proceedings_cnt |
|---|---|---|---|---|---|---|---|
| CCS | Tier 1 | 2179 | 2073 | 1993 | 2019 | 26 | 26 |
| Crypto | Tier 1 | 1266 | 1234 | 1981 | 2012 | 32 | 32 |
| Eurocrypt | Tier 1 | 1252 | 1220 | 1982 | 2014 | 33 | 32 |
| NDSS | Tier 1 | 853 | 829 | 1995 | 2019 | 25 | 25 |
| S&P (Oakland) | Tier 1 | 1548 | 1499 | 1980 | 2019 | 40 | 49 |
| Security | Tier 1 | 1779 | 1696 | 1993 | 2019 | 25 | 83 |
| ACSAC | Tier 2 | 1345 | 1304 | 1989 | 2019 | 30 | 34 |
| ASIACCS | Tier 2 | 846 | 832 | 2006 | 2019 | 14 | 14 |
| Asiacrypt | Tier 2 | 798 | 777 | 1990 | 2014 | 23 | 21 |
| CHES | Tier 2 | 639 | 618 | 1999 | 2018 | 20 | 21 |
| CSF (CSFW) | Tier 2 | 750 | 714 | 1988 | 2019 | 32 | 35 |
| DSN | Tier 2 | 1936 | 1841 | 2000 | 2019 | 20 | 37 |
| ESORICS | Tier 2 | 1014 | 971 | 1990 | 2020 | 25 | 43 |
| EuroS&P | Tier 2 | 253 | 246 | 2016 | 2019 | 4 | 7 |
| IMC | Tier 2 | 772 | 753 | 2001 | 2019 | 19 | 19 |
| PETS | Tier 2 | 227 | 213 | 2002 | 2014 | 13 | 13 |
| RAID | Tier 2 | 539 | 515 | 1999 | 2019 | 21 | 23 |
| TCC | Tier 2 | 477 | 462 | 2004 | 2016 | 12 | 15 |
2. Keyword Extraction
Title, the heap of major technology and ideas, is a high-level summary of a paper. Therefore, we directly extract keywords of conferences/proceedings from the titles of papers. We will not consider cryptography conferences in this keyword extraction task.
Dblp also provides external hyperlink of electronic edition of research papers. But to access the electronic version without permission from publishers may involve copyright issues, as they declared . Here we remain the abstract-level and fulltext-level tasks to the future.
2.1 Text cleaning
Four cleaning methods are applied to the dataset.
- Normalization : convert all words to lowercase, remove punctuation.
- Tokenization: split titles into multiple words.
- Removing stopwords : stopwords are commonly used words, e.g. "the", "a", "an".
- Stemming and Lemmatization : restore words to stem or root.
Original Text:
"many popular programs, such as netscape, use untrusted helper applications to process data from the network. unfortunately, the unauthenticated net- work data they interpret could well have been created by an adversary, and the helper applications are usually too complex to be bug-free."
After normalization:
'mani popular program netscap use untrust helper applic process data network unfortun unauthent work data interpret could well creat adversari helper applic usual complex'
2.2 TFIDF
We use TF-IDF to extract keywords.
TF-IDF (Term Frequency-InversDocument Frequency) is a numerical statistic that is intended to reflect how important a word is to a document in a collection or corpus. (Refers to WikiPedia)
- TF (Term Frequency) represents the frequency of a certain keyword in the article.
- IDF (InversDocument Frequency) stands for inverse document frequency, which is used to reduce the effect of some common words in all documents that have little effect on the document.
The TF-IDF calculation formula in sklearn is
-
is the frequency of keyword appearing in text .
-
-
is a keyword, is a text, represents the number of texts in the training set, and represents the total number of texts containing the keyword .
def keywords_extractor(level, corpus_from,tier):
data = get_corpus(level, corpus_from,tier=tier)
corpus = [i[2] for i in data]
vectorizer=CountVectorizer()
transformer=TfidfTransformer()
X=vectorizer.fit_transform(corpus)
tfidf=transformer.fit_transform(X)
word=vectorizer.get_feature_names()
weight=tfidf.toarray()
topx = 30
top_keywords_li = []
for i in range(weight.shape[0]):
sorted_keyword = sorted(zip(word, weight[i]), key=lambda x:x[1], reverse=True)
top_keywords = [w[0] for w in sorted_keyword[:topx]]
top_keywords_li.append(list(data[i][:2]) + top_keywords)
# print(top_keywords_li)
df = pd.DataFrame(top_keywords_li)
df.columns = ["%s" % level, "cnt"] + ["top%d" % i for i in range(1,topx + 1)]
df.to_csv("./nlp/top_keywords_%s_%s.csv" % (level, corpus_from), index=False)
2.2 Analysis
Let's first look at top10 keywords of tier1 conferences in the past 40 years. Click section Dataset to get the full version.
| year | cnt | top1 | top2 | top3 | top4 | top5 | top6 | top7 | top8 | top9 | top10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1980 | 19 | secur | system | preliminari | safeguard | key | data | report | cryptosystem | deceit | describ |
| 1981 | 18 | secur | system | protect | fund | half | lead | loaf | none | restricit | problem |
| 1982 | 20 | secur | allianc | blindfold | conseqeu | cryptanalyt | memoryless | neval | obm | oskar | restitut |
| …… | |||||||||||
| 2017 | 502 | attack | secur | detect | android | privaci | vulner | network | learn | analysi | via |
| 2018 | 542 | secur | attack | learn | deep | android | detect | use | network | analysi | adversari |
| 2019 | 590 | attack | secur | privaci | adversari | learn | apo | neural | deep | iot | fuzz |
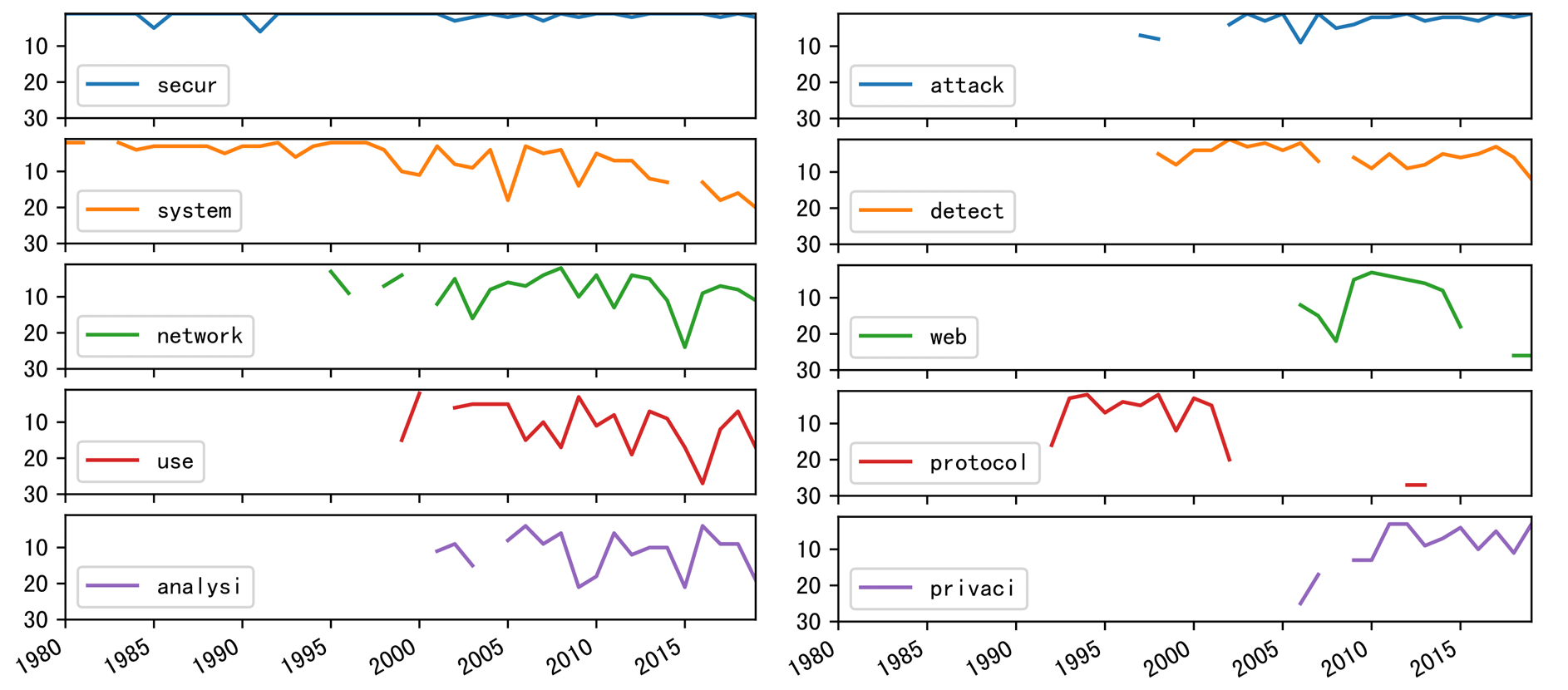
Horrible, right? Let's turn it into line charts.
Following are the top10 keywords in the past 40 years. They are
secur, system, attack, detect, network, use, analysi, privaci, data and protocol
.
-
The popularity of keyword
systemdecreases in recent years, same asnetwork; -
attackanddetect, like twins, rise at almost the same time, and experience similar trends. -
protocolrises in the 90s, and the popularity continues until the 05s. - ……
If we expand observation scope to top11-20 keywords, we can track more topics' trends. To get reach to more keywords, have a look at Section Title .
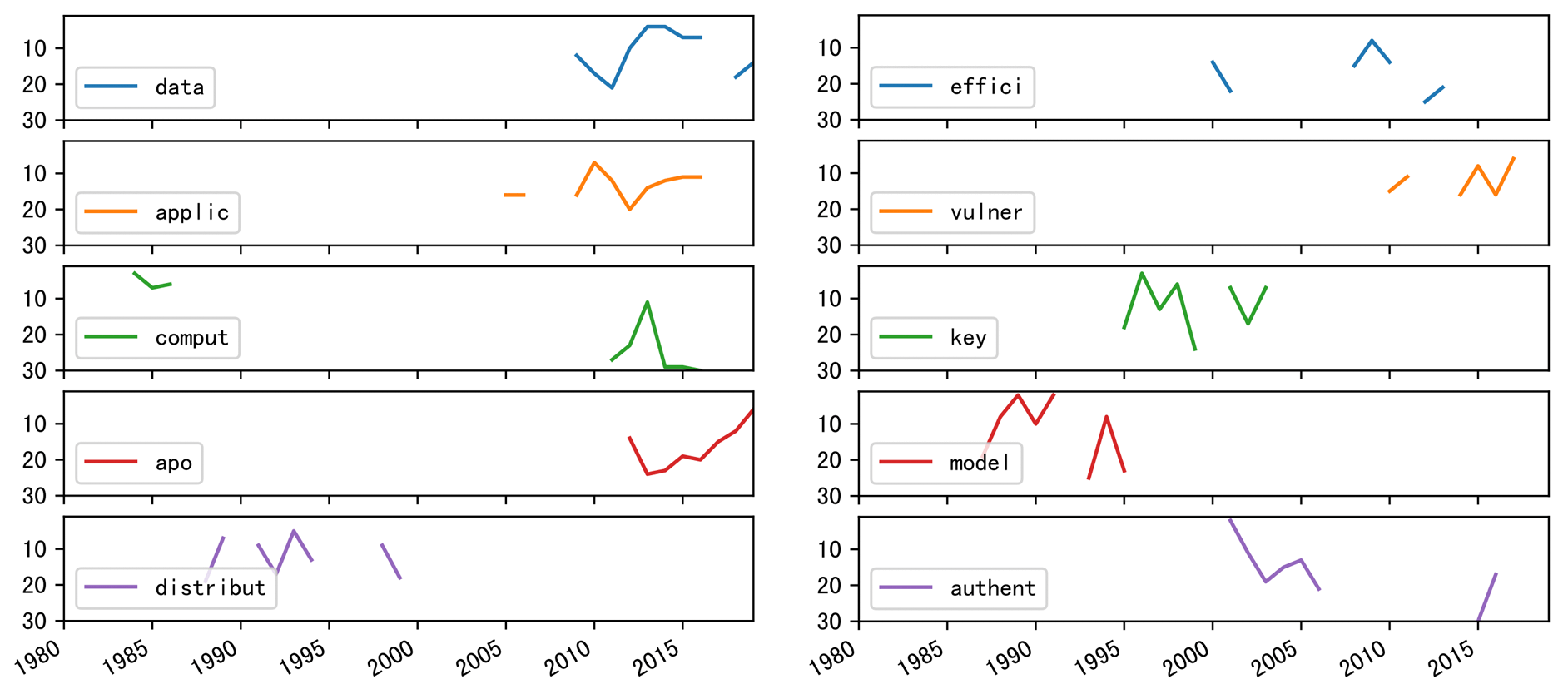
Now let's turn our attention to tier2 conferences.
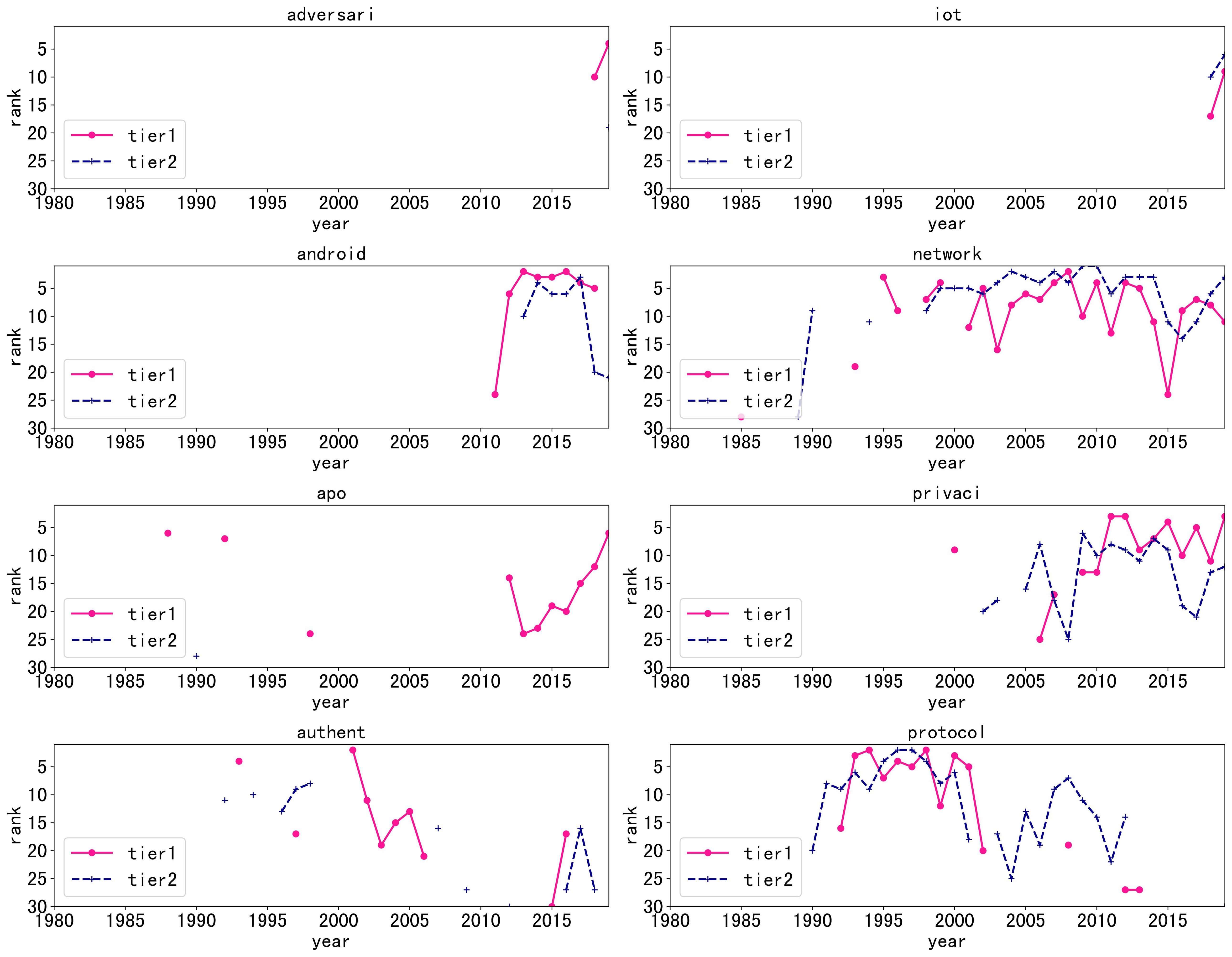
-
The popularity of tier1 and tier2 keywords appear in neighbor years. Sometimes, tier2 lags behind tier1 (
android); sometimes tier1s lag behind tier2(protocol). - The popularity of keywords in tier2 usually remains longer than tier1.
Same, you can find the full comparison charts at Section Tier1 VS Tier2 .
3. Other Findings
3.1 Title Length
The length of title gradually increases over 40 years. In 1996, the average length was still 57, and by 2020 this value had become 75.
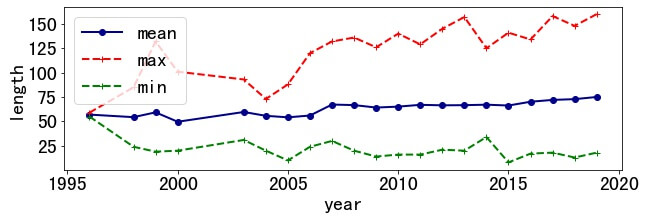
The shortest title is "Run-DMA." (length 8) and the longest title is "Security Scenario Generator (SecGen)-A Framework for Generating Randomly Vulnerable Rich-scenario VMs for Learning Computer Security and Hosting CTF Events." (length 158).
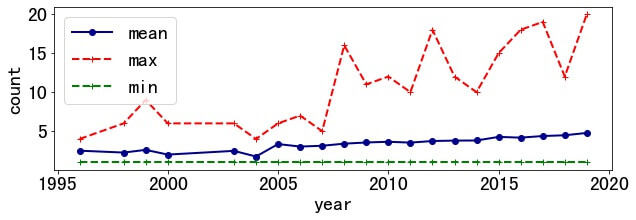
3.2 Authors per Paper
Authors per paper also increased. The average number increased from 2.5 in 1996 to 4.77 in 2019. The maximum number of paper authors is 20( "Five Years of the Right to be Forgotten." ), and the minimum is 1.
3.3 Subtitle Proposition
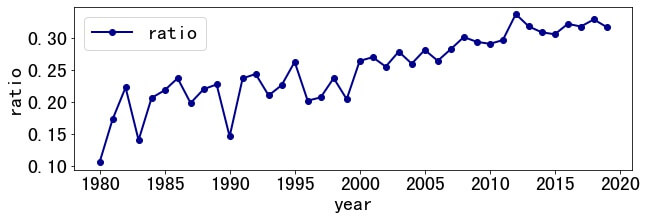
Due to some unknown reasons, subtitles (or mottos) are favored, such as "I Like It, but I Hate It-Employee Perceptions Towards an Institutional Transition to BYOD Second-Factor Authentication." . So, what is the proportion of papers with subtitles?
With researchers' efforts, the usage rate of subtitles increases from 10.53% in 1980 to 31.63% in 2019 and reached the highest record of 33.66% in 2012. XD
Among them, the most frequently used proverb is "Less is More" , which was used 3 times in 2014-2019.
4. Related Work
- System Security Circus 2019 : a data-driven analysis of publications and authorship on 6 security conferences.
- SecPrivMeta : a topic modeling on publications of S&P, CCS, NDSS, and USENIX.
Questions or ideas?
We welcome questions, discussions, and inspirations about
SecTrend Analysis
through e-mail to xinyue.shen@cispa.de
License
MIT © Vera Xinyue Shen